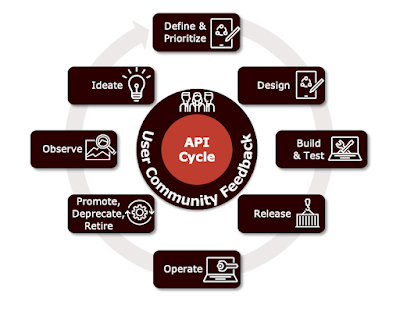
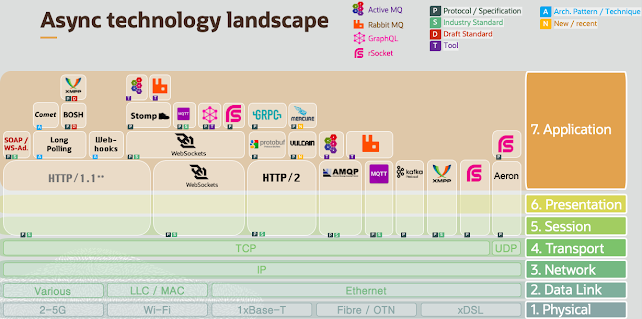
Demystifying the Model Context Protocol (MCP)

There has been a lot of noise about MCP "killing APIs" or being a revolutionary shift that makes traditional APIs obsolete. This is a red herring . The reality is simpler: MCP is a new Remote Procedure Call (RPC)-based protocol —arguably, also an API that wraps (abstracts) other existing APIs. APIs Aren’t Dead, They Evolve APIs have been evolving for decades, adapting to new paradigms in computing. From SOAP to REST , then GraphQL , event-driven APIs , and now MCP , we’ve seen a natural progression towards more dynamic, flexible interactions. But at its core, MCP is still a programming interface as it defines a structured way for systems to communicate, much like JSON-RPC 2.0, which it is based on. I encourage those who believe that MCP is an API killer to do a bit of homework and research the history of programming interfaces. In case it helps, here’s a research I did a few years back whilst writing Enterprise API Management . Understanding MCP Without the Hype Ok,...